
Логистическая компания получает заявки в свободной форме. «Привезите груз на склад на Дмитровском, рядом с пересечением с Ленинградкой, серое здание за ТЦ». Операторы вручную вбивают адреса в систему, тратя на одну заявку 3–5 минут. При сотне заявок в день это полный рабочий день одного человека, который мог бы решать задачи сложнее.
Это и есть задача геопарсинга — автоматического извлечения географических сущностей из текста и их привязки к реальным координатам. На первый взгляд кажется, что достаточно регулярного выражения для «улица + название». Но реальность куда сложнее.
Самая очевидная проблема: одно и то же название может означать совершенно разные места. «Тверская» — это улица в Москве, город в Тверской области, или сама область? «Петербург» — Санкт-Петербург или Петербург, штат Вирджиния, США? «Ленинградский» — проспект в Москве, район в Калининграде, или историческая ссылка?
Человек разрешает эти неоднозначности мгновенно, используя контекст. Если рядом упоминается «Москва», «метро», «Кремль» — очевидно, речь о московской улице. Если контекст — «Волга», «Ржев», «область» — это Тверь-город. Машина должна научиться тому же: понимать не отдельные слова, а их взаимосвязи в тексте. Задача геопарсинга — извлечь топонимы, разрешить неоднозначности и привязать к координатам.
Архитектура решения: четыре уровня понимания
Полноценный геопарсер работает в четыре этапа, каждый из которых решает свою задачу и передаёт результат следующему. Это похоже на то, как работает человеческое восприятие: сначала мы выхватываем знакомые паттерны, потом понимаем их значение в контексте, затем уточняем детали и наконец привязываем к реальному миру.
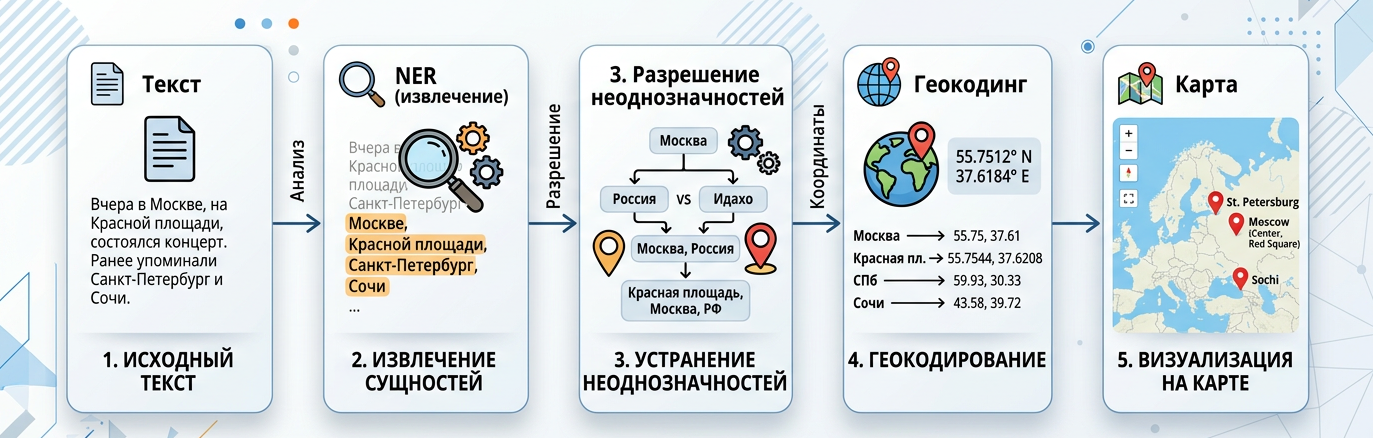
Первый уровень: извлечение сущностей (Named Entity Recognition)
На этом этапе задача — найти в тексте всё, что похоже на географическое название, не разбираясь пока, что именно это. Классические методы здесь работают плохо: регулярные выражения ловят «ул. Ленина» но пропускают «на Ленинградке», потому что «Ленинградка» — разговорное сокращение, не попадающее в стандартные паттерны.
Современные решения используют нейронные сети, обученные на размеченных корпусах текстов. Модели семейства BERT и её производные (RuBERT для русского языка) показывают качество распознавания около 90–95% на стандартных тестах. Они учитывают не только сами слова, но и их окружение — соседние слова, пунктуацию, структуру предложения.
Второй уровень: разрешение неоднозначностей
Найдя «Тверскую», система должна понять, о какой именно. Здесь работают три механизма:
Иерархический контекст. Если в том же предложении или абзаце есть «Москва», вероятность того, что Тверская — московская, резко возрастает. Это работает рекурсивно: «Москва» → «Центральный округ» → «Тверская улица» → «дом 1». Система строит дерево возможных интерпретаций и выбирает наиболее полную и связную ветвь.
Статистика совместной встречаемости. В больших корпусах текстов можно посчитать, как часто встречаются пары топонимов. «Тверская» + «Москва» — тысячи раз. «Тверская» + «Тверь» — сотни. «Тверская» + «Владивосток» — единицы. Эти вероятности используются как веса при выборе между вариантами.
Географическая близость. Если уже распознаны другие топонимы в тексте, система предпочитает варианты, находящиеся относительно близко. Если речь о событиях в Москве, «Ленинградский проспект» выбирается в пользу одноимённого района Калининграда.
Третий уровень: нормализация и дополнение
Разрешённое название нужно привести к стандартному виду, пригодному для геокодинга. «Ленинградка» → «Ленинградский проспект». «На Дмитровке» → «Дмитровское шоссе». «За ТТК» → «за пределами Третьего транспортного кольца, Москва».
Этот этап часто требует словарей синонимов и разговорных форм, составленных вручную или полуавтоматически на основе анализа реальных текстов. Для новых объектов (свежих ТЦ, жилых комплексов) эти словари приходится регулярно обновлять.
Четвёртый уровень: геокодинг
Финальный шаг — превращение текстового описания в координаты. Здесь используются геокодинговые сервисы: Nominatim (базируется на OpenStreetMap), Яндекс.Геокодер, Google Geocoding API. Они сопоставляют нормализованное название с объектами в базе данных и возвращают широту, долготу, тип объекта (улица, здание, город), ограничивающий прямоугольник.
Критически важно кэширование на этом этапе. Геокодинг — дорогая операция, как по времени (сетевой запрос), так и по деньгам (платные API). Повторные запросы для «Москва, Красная площадь» должны браться из кэша мгновенно.
Новостные агентства и службы экстренного реагирования используют геопарсинг для построения карт событий в реальном времени. Система сканирует тысячи источников — социальные сети, мессенджеры, новостные ленты — и наносит упоминаемые локации на карту. Аналитик видит кластеры: здесь сейчас протесты, там ДТП, вон там пожар. Географическая визуализация позволяет быстрее оценивать масштаб и распределять ресурсы.